Контейнеризация. Часть 1. Введение и изоляция процессов
Если взять всех разработчиков, которые в 2025 году ни разу не пользовались Docker’ом, то мы получим только лишь счастливых фронтендеров, потому что для них контейнер – это <div class="container" />. Шучу. Счастливые фронтендеры - не разработчики.
И все же для запуска кода ниже вы не обязательно должны работать DevOps’ом:
docker run -e POSTGRES_PASSWORD=mysecretpassword \
-v ./pg-data:/var/lib/postgresql/data \
-p 5432:5432 -d postgres
Контейнеры везде. Однако можете ли вы ответить на вопрос, как они работают? Вы мне возразите, ответив на мой вопрос вашим:
“А зачем мне понимать? Если что-то непонятно я всегда могу спросить у дипсика! А я лучше сосредоточусь на том, что больше улучшает мою реальность - как с помощью знаний дипсика заработать деньги”
Почему это вообще важно
Кажется вам, что вы раскрыли мою наивную групость и желание графоманства? Я, в попытках скрасить собственные будни, уйдя в забвение от отсутствия Мазерати, буду вам рассказывать, что такое контейнеризация и виртуализация, хотя на самом деле это знание совсем бесполезно? Что-ж, я признаю вашу позицию блаженного неведения.
Однако позвольте все-таки прояснить мою позицию: подобные фундаментальные знания в области CS позволяют вам смотреть на программное обеспечение по другому. И у такого взгляда есть три силы:
- Он умеет диагностировать, понимать истинную причину проблем и идти с корня наверх, а не наобум из-за незнания;
- Он умеет задавать вопросы там, где вы бы их не задали из-за незнания;
- Он умеет видеть решения, которых вы не видите из-за незнания;
Однажды я потратил пару дней на то, чтобы с помощью GPT разобраться, почему IPv6 сеть в Docker’е не работает так, как я ожидаю. А потом все таки пошел читать про устройство сетей в Docker.
Постулирую, что изучение подобных вещей важно по той причине, что расширяя собственную базу данных, а не пользуясь чужой, вы способны куда лучше находить и решать проблемы, обнаруживать узкие и небезопасные места в архитектурных решениях и главное - вы способны придумывать необычное и новое. Эти навыки позволяют вам, как минимум, лучше зарабатывать деньги. Как максимум, находить в этом аспекты творчества и реализации
Контейнеры in nutshell
Представь. Ты - счастливый JS’er, зарабатывающий 500к в наносекунду, и твое гига enterprise production ready приложение (сгенеренный CRUD на express с Prisma) должно запуститься по-хорошему не только у тебя, но и у клиентов. За это полагается премия! Поэтому ты идешь деплоить его в некое облако… на какую-то виртуальную машину… а еще какой-то бородач на созвоне сказал, что надо написать докерфайл… Почему же нельзя просто тарник через scp закинуть и запустить на этом вашем линуксе?
Главная проблема - это то, что для запуска твоего шедевра нужен Node JS, а еще npm для установки зависимостей. И на самом деле может быть нужно еще куча всего, в зависимости от характера приложения. Так или иначе, дело в окружении твоего приложения. Для того, чтобы запустить твой говно-круд, нужно воссоздать определенное окружение, то есть набор утилит, библиотек и прочее ПО. Более того, иногда от приложения к приложению версии этого ПО может быть разное. И разные версии могут конфликтовать в рамках одной хостовой машины, или по крайней мере доставлять неудобства. В итоге мы приходим к тому, что где-то твое приложение работает, где-то почти работает, но кусок функционала отваливается, а где-то вообще не запускается. И все дело в окружении и некорректных зависимостях!
Спасибо, что на планете есть не только счастливые JS’ры, поэтому, видимо менее счастливые, но более умные люди выдвинули тезис:
“А что если упаковывать приложения не просто в тарник, а в такой тарник, где помимо приложения будут все необходимые зависимости, включая операционную систему?”
Так и появился термин контейнер. Контейнер - это изолированная упакованная среда, внутри которой содержится программное обеспечение и все необходимые зависимости для его работы. Можно думать об этом, как о некой "коробке", в которой есть все, что требуется вашему приложению. И для того, чтобы запустить приложение, есть единственное требование - чтобы хостовая среда поддерживала контейнеризацию.
Механизм работы контейнеров на примере Linux
Лично меня не устраивает понятие "коробка". Разве мы, настоящие инженеры, способны остановить свою жажду познания на какой-то жалкой человеческой, хоть и достаточно изящной метафоре? С этого момента я запрещаю использование слово коробка. Теперь мы оперируем только пространствами имен(namespaces) и cgroups
Итак, представьте Саню, который решил запустить постгрю в контейнере:
docker run -it --rm postgres sh
И чем же отличается этот Санин контейнер он "не контейнера", то есть операционной системы? Во-первых, мы имеем другую файловую систему:
# ls
bin boot dev docker-entrypoint-initdb.d etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Здесь нет Саниного ./secret_folder/python_projects, который он так часто открывает на хостовой машине! И во-вторых, здесь есть psql:
# psql
psql: error: connection to server on socket "/var/run/postgresql/.s.PGSQL.5432" failed: No such file or directory
Is the server running locally and accepting connections on that socket?
выйдя из контейнера мы наблюдаем, что psql действительно нет:
root@backend:/home/alexzhaba# psql
Command 'psql' not found, but can be installed with:
apt install postgresql-client-common
Благо пед проект остался целым и невредимым:
root@backend:/home/alexzhaba# tree secret_folder/
secret_folder/
└── python_projects
└── my-first-todo-app-on-djange
2 directories, 0 files
SO, давайте попробуем самостоятельно сварганить такой контейнер, без помощи докера.
Namespaces
Основной механизм, с помощью которого достигается так называемая изоляция у контейнера - это пространства имен Linux, или namespaces. Namespace - это способ изоляции ресурсов для определенного процесса.
Из этого определения давайте вычленим некоторые выводы. Во-первых, namespace - это атрибут процесса. Namespace жив только тогда, когда он привязан к какому либо процессу. Во-вторых, namespace - это не какой-то магический инструмент для создания маленьких операционных систем внутри другой, это способность ограничивать “контекст” процесса засчет некой надстройки. Читая в интернете тезисы по типу "Вы можете задумываться о namespace’ах, как о коробках", не забывайте, что:
Если namespace называть коробкой, то нужно учитывать, что вы НЕ помещаете требуемый для изоляции процесс в это коробку. Скорее при запуске процесса вы формируете такие ограничения, которые не позволяют изолированному процессу смотреть наружу.
Это станет более понятно, когда мы будем копаться в кишках Docker’a, а пока давайте перейдем от сухих слов к нажатию хоть каких-то кнопок.
Итак, раз мы утверждаем, что namespace - атрибут процесса, то и для процесса открытого shell’a есть это пространство имен? Да! Давайте убедимся в этом, просмотрев в специальной директории файлы для текущего процесса ($ $):
root@backend:/home/alexzhaba# echo $$
4060225
root@backend:/home/alexzhaba# ls /proc/$$/ns -al
total 0
dr-x--x--x 2 root root 0 Jun 4 21:57 .
dr-xr-xr-x 9 root root 0 Jun 4 21:57 ..
lrwxrwxrwx 1 root root 0 Jun 4 21:57 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 net -> 'net:[4026531840]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Jun 4 21:57 uts -> 'uts:[4026531838]'
Здесь ns - это namespaces. Благодаря этой команде мы видим, что на самом деле пространства имен существуют в разрезах разных ресурсов. Обычно выделяют 8 типов namespace’ов: cgroup, ipc, mnt, net, pid, time, user, uts. Как видно из вывода, для текущего процесса есть namespace типа mnt с идентификатором 4026531841. У нас нет желания подробно останавливаться на uts, time, ipc пространствах. Net очень важен, но его использование и связь с Docker тянет на отдельную статью. User намерено отложим, сосредоточив свое внимание на cgroup, mnt и pid.
Окей, давайте попробуем создать изолированный процесс! Для этого существует команда unshare, которая даже своим названием косвенно говорит "то, чем делиться не буду!". Unshare позволяет создать новые namespace’ы разного типа для запускаемого процесса. Сперва давайте убедимся, что:
- На хостовой тачке есть папка по пути
/home/alexzhaba/secret_folder:
root@backend:/home/alexzhaba# tree /home/alexzhaba/secret_folder/
/home/alexzhaba/secret_folder/
└── python_projects
└── my-first-todo-app-on-djange
2 directories, 0 files
- Есть куча разных запущенных процессов:
root@backend:/home/alexzhaba# ps aux | wc -l
195
Давайте запустим в текущем процессе изолированный bash:
root@backend:/home/alexzhaba# sudo unshare bash
Однако, ничего не произошло… все как было, так и осталось:
root@try-self-backend:/home/alexzhaba# ps aux | wc -l
196
root@try-self-backend:/home/alexzhaba# tree /home/alexzhaba/secret_folder/
/home/alexzhaba/secret_folder/
└── python_projects
└── my-first-todo-app-on-djange
2 directories, 0 files
Может что-то все таки поменялось, но мы не видим? Как проверить?..
Если вы знаете как - поздравляю, у вас нет СДВГ и вы помните, что прочитали минуту назад. Мы же можем просто сравнить идентификаторы namespace’ов!
root@backend:/home/alexzhaba# echo $$
4062144
root@backend:/home/alexzhaba# ls /proc/$$/ns -al
total 0
dr-x--x--x 2 root root 0 Jun 4 22:22 .
dr-xr-xr-x 9 root root 0 Jun 4 22:20 ..
lrwxrwxrwx 1 root root 0 Jun 4 22:22 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 net -> 'net:[4026531840]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Jun 4 22:22 uts -> 'uts:[4026531838]'
При условии, что PID активного процесса отличается, id namespace’ов одинаковые. Так мы узнали, что команда unshare по умолчанию клонирует пространства активного процесса при запуске нового! Но давайте все таки теперь запустим unshare c созданием нового PID namespace:
root@backend:/home/alexzhaba# unshare --pid bash
bash: fork: Cannot allocate memory
It’s over! МЫ СЛОМАЛИ ЛИНУКС! А что ожидалось собственно? Давайте сформулируем – мы:
- Запустимся в рамках нового PID процесса;
- с новым PID namespace;
- и не будем видеть все другие процессы… Но пока не очень понимаем, что это до конца значит;
Что-ж, ну мы как минимум действительно в другом процессе:
root@backend:/home/alexzhaba# echo $$
12443
root@backend:/home/alexzhaba# unshare --pid bash
bash: fork: Cannot allocate memory
root@backend:/home/alexzhaba# echo $$
12705
А вот узнать другое мы не можем:
root@try-self-backend:/home/alexzhaba# ls /proc/$$/ns -al
bash: fork: Cannot allocate memory
root@try-self-backend:/home/alexzhaba# ps aux
bash: fork: Cannot allocate memory
Поэтому мы создадим новую терминальную сессию и через PID процесса узнаем, какой у него namespace:
root@backend:/home/alexzhaba# ls /proc/12705/ns -al | grep pid
lrwxrwxrwx 1 root root 0 Jun 14 15:55 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jun 14 15:55 pid_for_children -> pid:[4026532790]
Мы видим очень странную картину: с одной стороны PID namespace у нашего unshare процесса не поменялся, при этом некий pid_for_children новый… НЕПОНЯТНО!
Лирическое отступление про процессы в Linux
Для того, чтобы понять такое поведение команды unshare --pid bash, нам, как ни странно, требуется ответить на вопрос: что же все таки означает изоляция процесса от других процессов?
Процессы в линуксе имеют иерархическую структуру: каждый является дочерним для своего родителя, кроме корневого: так называемого init процесса. За счет чего создается подобная иерархия? В основном засчет двух способов порождения дочерних процессов: системные вызовы fork и clone.
Fork создает новый процесс. При этом тот процесс, который и вызывает fork, становится родительским для этого нового процесса. В принципе можно легко узнать, кто чей родитель, и даже ДНК-тест сдавать не придется - достаточно /proc/PID/status :
root@backend:/home/alexzhaba# cat /proc/$$/status | grep -E "Pid|PPid"
Pid: 82892
PPid: 82891
TracerPid: 0
Pid - идентификатор процесса, PPid - идентификатор родителя. Если бы Дарвин составлял классификацию видов, то, читая данный текст, он явно бы сформулировал следующий вопрос, дабы отличить Homo Sapiens от шимпанзе (они кстати умные, так что не расстраивайтесь, если не ответите!): что будет, если постоянно брать PPid, проверять его статус, брать его PPid, проверять его статус и так далее?..
Я думаю, вы, дорогой читатель, справились и ответили правильно! Ведь вы наверняка запомнили, что процессы иерархичны. Как следствие, постоянно проверяя статус PPid мы будем карабкаться идти наверх по этому дереву, и в какой-то момент упремся в Pid 1 - нам знакомый init процесс.
Так, например, выглядит htop, который запущен внутри нашей текущей терминальной сессии:

И как видите, htop - это дочерний процесс для bash.
Окей, а clone - это что за чудо такое? Это такой же fork, только с дополнительной возможностью ограничивать контекст процесса и связь между родителем - дочерним. Например, можно контролировать, шарятся ли между процессами файловые дескрипторы. Но для нас интересней, что с помощью clone можно поместить процесс с отдельные namespace. В контексте PID namespace для этого используется флаг **CLONE_NEWPID**
А теперь обратите внимание на схему:
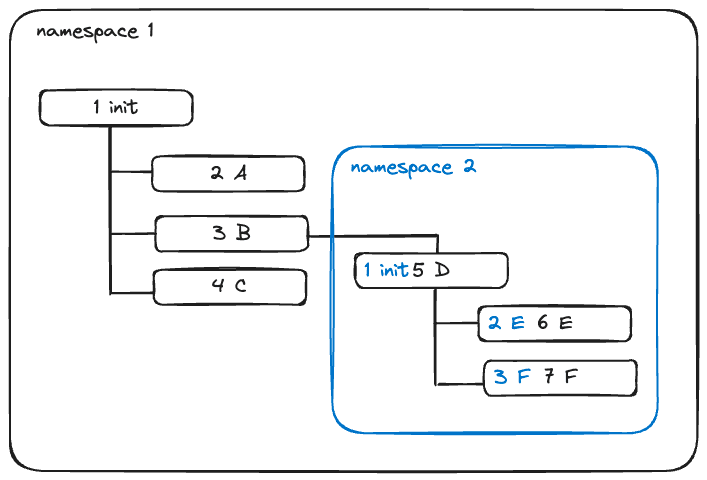
При создании нового PID namespace процессы, которые в нем крутятся, все так же существуют в одном дереве процессов Linux. Но прикол в том, что процессы D, E, F имеют уникальные идентификаторы в namespace, и видят они себя и друг друга именно так! Причем обратите внимание, дорогой читатель - у namespace 2 точно также есть init процесс под идентификатором 1. И в случае с запуском через unshare - это тот процесс, который мы указываем при запуске . (bash в случае unshare --pid bash).
Итак, возвращаясь к вопросу:
что же все таки означает изоляция процесса от других процессов?
Это означает создание процесса с новым pid namespace, который становится init процессом, после чего он и все его дочерние процессы имеют собственные уникальные Pid внутри namespace и не имеют доступа до процессов, выше корневого (init) для namespace.
Что же случилось с bash в unshare?
Базовое поведение bash оболочки при запуске внешних программ - это:
- сделать fork самого себя, получив новый PID;
- внутри нового процесса с PID запустить программу через exec или подобные ему инструкции, заменяющие активный процесс новой программой.
А теперь достаем монокль, одеваем шляпу, и раскручиваем, что же случилось, когда мы написали:
root@backend:/home/alexzhaba# unshare --pid bash
Мы, находясь в оболочке bash, запускаем команду unshare с созданием PID процесса и запуском в качестве init процесса bash… Вот только ньюанс - а как вызывается bash? Он форкается от unshare или спавнится просто в дереве процессов? не буду вас мучать проверкой через proc/$ $/status. По умолчанию unshare запускает процесс, не форкая его. При этом сам unshare вызывается с флагом CLONE_NEWPID (–pid). Обратимся в документации pid_namespaces:
The first process created in a new namespace (i.e., the process created using clone(2) with the CLONE_NEWPID flag, or the first child created by a process after a call to unshare(2) using the CLONE_NEWPID flag) has the PID 1, and is the “init” process for the namespace (see init(1)).
Итого получается: мы запускаем bash через unshare с CLONE_NEWPID, но при этом не форкаем его, то есть не делаем дочерним для unshare. Из-за чего bash не становится init процессом и тем самым namespace просто перестает существовать.
ВЫВОД:
Надо добавить флаг --fork при запуске, чтобы bash был дочерним для unshare, и чтобы он был корректно запущен в рамках pid namespace, став init процессом.
Окей, делаем:
root@backend:/home/alexzhaba# unshare --pid --fork bash
root@backend:/home/alexzhaba# echo $$
1
Наконец победа! Или…
root@backend:/home/alexzhaba# ls /proc/$$/ns -al | grep pid
lrwxrwxrwx 1 root root 0 Jun 21 14:02 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jun 21 14:02 pid_for_children -> pid:[4026531836]
root@backend:/home/alexzhaba# unshare --pid --fork bash
root@backend:/home/alexzhaba# ls /proc/$$/ns -al | grep pid
lrwxrwxrwx 1 root root 0 Jun 15 11:04 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jun 21 14:01 pid_for_children -> pid:[4026531836]
root@backend:/home/alexzhaba# echo $$
1
root@backend:/home/alexzhaba# ps aux | wc -l
175
Да, мы внутри действительно теперь Pid 1, но:
- неймспейс не поменялся;
- мы все также видим все процессы.
Вы скажете, что это невыносимо! Я скажу - да. Более того, я себе позволю добавить флаг, не объяснив, что он делает, но который полностью решает все проблемы.
И имя ему ---mount-proc:
root@try-self-backend:/home/alexzhaba# ls /proc/$$/ns -al | grep pid
lrwxrwxrwx 1 root root 0 Jun 21 14:02 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jun 21 14:02 pid_for_children -> pid:[4026531836]
root@backend:/home/alexzhaba# unshare --pid --fork --mount-proc bash
root@backend:/home/alexzhaba# ls /proc/$$/ns -al | grep pid
lrwxrwxrwx 1 root root 0 Jun 21 14:11 pid -> pid:[4026532787]
lrwxrwxrwx 1 root root 0 Jun 21 14:11 pid_for_children -> pid:[4026532787]
root@backend:/home/alexzhaba# ps aux | wc -l
4
Ну и чудеса! Теперь мы реально не видим других процессов, у нас новый namespace, и вообще шоколад! Проблема в том, что требуется еще больше теории для того, чтобы объяснить, что делает чудо mount-proc. Потому что помимо всех этих колдунств этот флаг внес еще небольшое изменение:
root@backend:/home/alexzhaba# ls /proc/$$/ns -al | grep mnt
lrwxrwxrwx 1 root root 0 Jun 21 14:02 mnt -> mnt:[4026531841]
root@backend:/home/alexzhaba# unshare --pid --fork --mount-proc bash
root@backend:/home/alexzhaba# ls /proc/$$/ns -al | grep mnt
lrwxrwxrwx 1 root root 0 Jun 21 14:14 mnt -> mnt:[4026532786]
У нас поменялся другое пространство имен - mount namespace!
Продолжение в следующей статье